
Guide to Mastering Duplicate Content Issues
The Complete Guide to Mastering Duplicate Content Issues
In the SEO arena of website architecture, there is little doubt that eliminating duplicate content can be one of the hardest fought battles.
Too many content management systems and piss-poor developers build sites that work great for displaying content but have little consideration for how that content functions from a search-engine-friendly perspective.
And that often leaves damaging duplicate content dilemmas for the SEO to deal with.
There are two kinds of duplicate content, and both can be a problem:
Onsite duplication is when the same content is duplicated on two or more unique URLs of your site. Typically, this is something that can be controlled by the site admin and web development team.
Offsite duplication is when two or more websites publish the exact same pieces of content. This is something that often cannot be controlled directly but relies on working with third-parties and the owners of the offending websites.
Why Is Duplicate Content a Problem?
The best way to explain why duplicate content is bad is to first tell you why unique content is good.
Unique content is one of the best ways to set yourself apart from other websites. When the content on your website is yours and yours alone, you stand out. You have something no one else has.
On the other hand, when you use the same content to describe your products or services or have content republished on other sites, you lose the advantage of being unique.
Or, in the case of onsite duplicate content, individual pages lose the advantage of being unique.
Look at the illustration below. If A represents content that is duplicated on two pages, and B through Q represents pages linking to that content, the duplication causes a split the link value being passed.
Now imagine if pages B-Q all linked to only on page A. Instead of splitting the value each link provides, all the value would go to a single URL instead, which increases the chances of that content ranking in search.
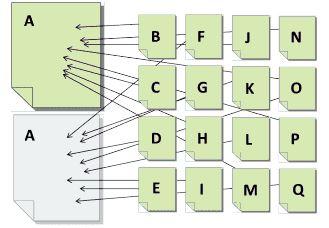
Whether onsite or offsite, all duplicate content competes against itself. Each version may attract eyeballs and links, but none will receive the full value it would get if it were the sole and unique version.
However, when valuable and unique content can be found on no more than a single URL anywhere on the web, that URL has the best chance of being found based on it being the sole collector of authority signals for that content.
Now, having that understanding, let’s look at the problems and solutions for duplicate content.
Offsite Duplicate Content
Offsite duplication has three primary sources:
- Third-party content you have republished on your own site. Typically, this is in the form of generic product descriptions provided by the manufacturer.
- Your content that has been republished on third-party sites with your approval. This is usually in the form of article distribution or perhaps reverse article distribution.
- Content that someone has stolen from your site and republished without your approval. This is where the content scrapers and thieves become a nuisance.
Let’s look at each.
Content Scrapers & Thieves
Content scrapers are one of the biggest offenders in duplicate content creation. Spammers and other nefarious perpetrators build tools that grab content from other websites and then publish it on their own.
For the most part, these sites are trying to use your content to generate traffic to their own site in order to get people to click their ads. (Yeah, I’m looking at you, Google!)
Unfortunately, there isn’t much you can do about this other than to submit a copyright infringement report to Google in hopes that it will be removed from their search index. Though, in some cases, submitting these reports can be a full-time job.
Another way of dealing with this content is to ignore it, hoping Google can tell the difference between a quality site (yours) and the site the scraped content is on. This is hit and miss as I’ve seen scraped content rank higher than the originating source.
What you can do to combat the effects of scraped content is to utilize absolute links (full URL) within the content for any links pointing back to your site. Those stealing content generally aren’t in the business of cleaning it up so, at the very least, visitors can follow that back to you.
You can also try adding a canonical tag back to the source page (a good practice regardless). If the scrapers grab any of this code, the canonical tag will at least provide a signal for Google to recognize you as the originator.

Read more: https://www.searchenginejournal.com/technical-seo/duplicate-content-issues/



