
How to Produce Quality Titles and Meta Descriptions Automatically
How to Produce Quality Titles & Meta Descriptions Automatically. difficult times it is more important than ever to get more effective work done in less time and with fewer resources.
One boring and time-consuming SEO task that is often neglected is writing compelling titles and meta descriptions at scale.
In particular, when the site has thousands or millions of pages.
It is hard to put on the effort when you don’t know if the reward will be worth it.
In this column, you will learn how to use the most recent advances in Natural Language Understanding and Generation to automatically produce quality titles and meta descriptions.
We will access this exciting generation capability conveniently from Google Sheets. We will learn to implement the functionality with minimal Python and JavaScript code.
Here is our technical plan:
- We will implement and evaluate a couple of recent state of the art text summarization models in Google Colab
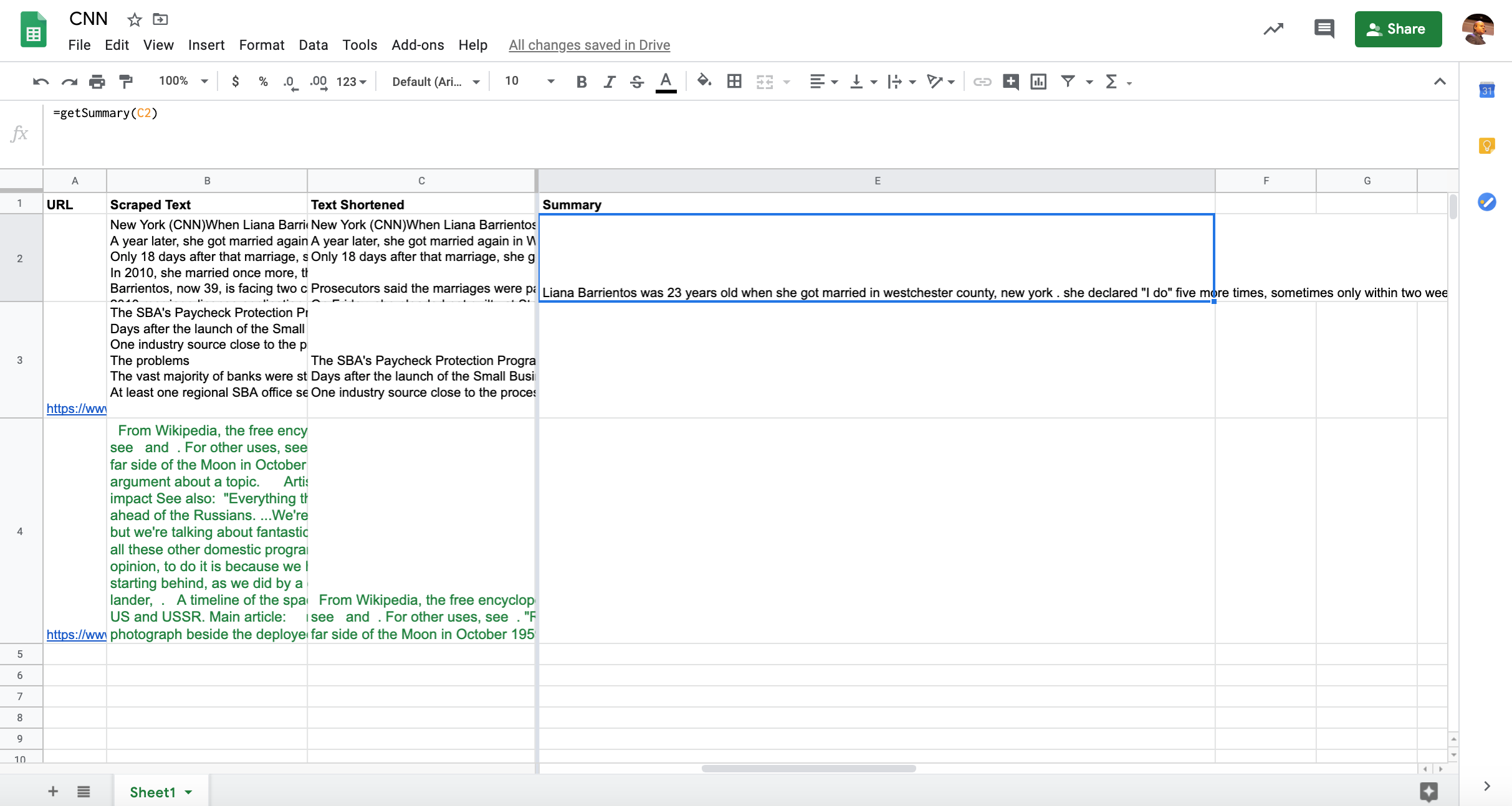
- We will serve one of the models from a Google Cloud Function that we can easily call from Apps Script and Google Sheets
- We will scrape page content directly from Google Sheets and summarize it with our custom function
- We will deploy our generated titles and meta descriptions as experiments in Cloudflare using RankSense
- We will create another Google Cloud Function to trigger automated indexing in Bing
Introducing Hugging Face Transformers
Hugging Face Transformers is a popular library among AI researchers and practitioners.
It provides a unified and simple to use interface to the latest natural language research.
It doesn’t matter if the research was coded using Tensorflow (Google’s Deep Learning framework) or Pytorch (Facebook’s framework). Both are the most widely adopted.
While the transformers library offers simpler code, it isn’t as simple enough for end users as Ludwig (I’ve covered Ludwig in previous deep learning articles).
That changed recently with the introduction of the transformers pipelines.
Pipelines encapsulate many common natural language processing use cases using minimal code.
They also provide a lot flexibility over the underlying model usage.
We will evaluate several state of the art text summarization options using transformers pipelines.
We will borrow some code from the examples in this notebook.
Read more: searchenginejournal



